Welcome to the second issue of Agents in Practice!
To write the newsletter, I have been going through a lot of papers and blog posts, and it has been a fulfilling experience. I hope that this filtered content is useful to you, and I would love to hear your feedback on what you would like to see in future issues.
FastContext: Specialized repo explorer for coding agents
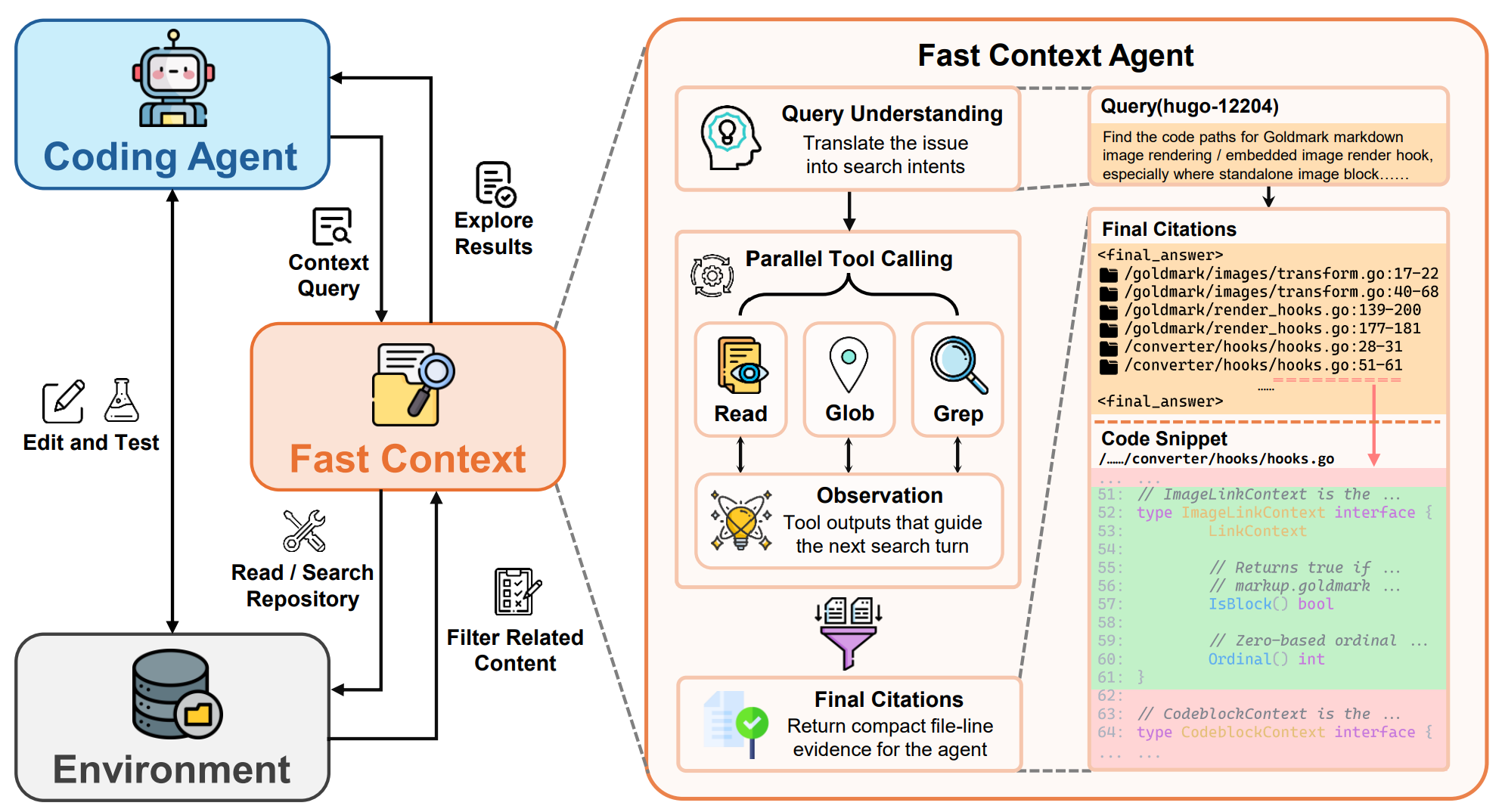
Reading and searching take up a significant amount of tool turns and tokens. In the trajectory analysis from the paper, the authors find that reading and searching account for 56.2% of tool-use turns and 46.5% of main-agent tokens, roughly comparable to the amount of work spent editing and testing code. This means that more efficient exploration could improve coding agents both in tokens spent and in waiting time before the coding phase.
The authors propose “FastContext,” a runtime delegation mechanism where the main agent asks an explorer subagent to perform repository exploration and return evidence rather than a patch. The subagent is fine-tuned with task-grounded RL and only has three basic tools: line-number-based Read, Glob, and regex-based Grep. After parallel tool calling, the subagent returns file paths and line ranges as evidence, which the main agent can then use for editing and testing. On three benchmarks (SWE-bench Pro, SWE-bench Multilingual, and SWE-QA), FastContext improves end-to-end accuracy while reducing main-agent tokens by roughly 9-60%, depending on the model and benchmark.
Personal Thoughts
One caveat is that the main table in the paper reports main-agent tokens, not total system tokens. The benefit can still be meaningful, though, because main agents use expensive solver tokens. The authors audit subagent overhead in one GPT-5.4 SWE-bench Multilingual run and find that the explorer used 22.58M subagent tokens across 300 tasks, which is still less than the roughly 35.7M GPT-5.4 main-agent tokens saved in that run. Under their pricing assumptions, the main-agent cost drops by $73.55 while the explorer would add $4.52 of subagent cost. This shows how good routing of tasks to smaller subagents can reduce cost while improving performance.
Read more
Agentic Resource Discovery: protocol for discovering agentic resources

Agentic Resource Discovery (ARD) is a discovery protocol for services that can answer questions like “What resources are available for this task?” by returning matching agentic resources. (It is not an execution runtime; it helps the AI client find a resource before that resource is invoked through its own mechanism.) ARD describes “agentic resource” as a broad thing encompassing “an agent, MCP server, Skill, Canvas, Plugin, API, or workflow” - so anything the AI agent could use in its trajectory to complete a task. It is being developed by contributors from organizations including GitHub, Google, Hugging Face, Microsoft, NVIDIA, and others, and some already have ARD-based discovery implementations, such as GitHub’s Agent Finder and Hugging Face’s Discover Tool.
Personal Thoughts
With how many new skills, MCP servers, and tools are created and advertised every week, finding the “right” set of resources to solve a task will become more and more difficult. It is easy to stick to a single set of resources that works after some exploration, but this risks using outdated or underperforming resources when there could be so many tools discoverable by the agent. Discovery is a hard task, and it will be interesting to see if ARD or other such protocols get widely adopted.
Read more
Personal Anecdote: benchmarking agentic models for personal use

Last weekend I ran a small model sweep on a small benchmark. I expected the expensive frontier models to dominate, but the result was messier: DeepSeek V4 Pro with default reasoning became the best practical default after validation, while Sonnet 4.6 had the best single run and Opus 4.8 was expensive for its score. It showed that agent model selection has to be treated like an experiment instead of a “choose the top one from a benchmark” decision, and that validation and cost accounting can change the conclusion.
It also gave me a reality check on how expensive agentic benchmarks are. In the RL world, the Arcade Learning Environment (ALE), which encapsulated Atari 2600 games into RL environments, was popular, but it was also too expensive to run for independent researchers. This resulted in the creation of various alternatives like MinAtar. With agentic benchmarks being even more expensive (full SWE-bench runs can cost thousands of dollars), it would be interesting to see what alternative benchmarks emerge in the research community.