Welcome to the first issue of Agents in Practice! This is a weekly newsletter that summarizes exciting new research and applications related to agentic AI. Because I am studying / developing / using agentic AI, I will also include my personal anecdote of what I have been doing with agents.
In each issue, I will try to pick 1 research paper, 1 benchmark or evaluation-related item, and 1 anecdote. But this may change over time as it will likely focus on news I deem exciting or fun to read about.
Welcome to our journey with agents!
📬 Agents in Practice is a weekly newsletter on agentic AI research and applications. Subscribe here →
Retrospective Harness Optimization: learning from unlabeled trajectories
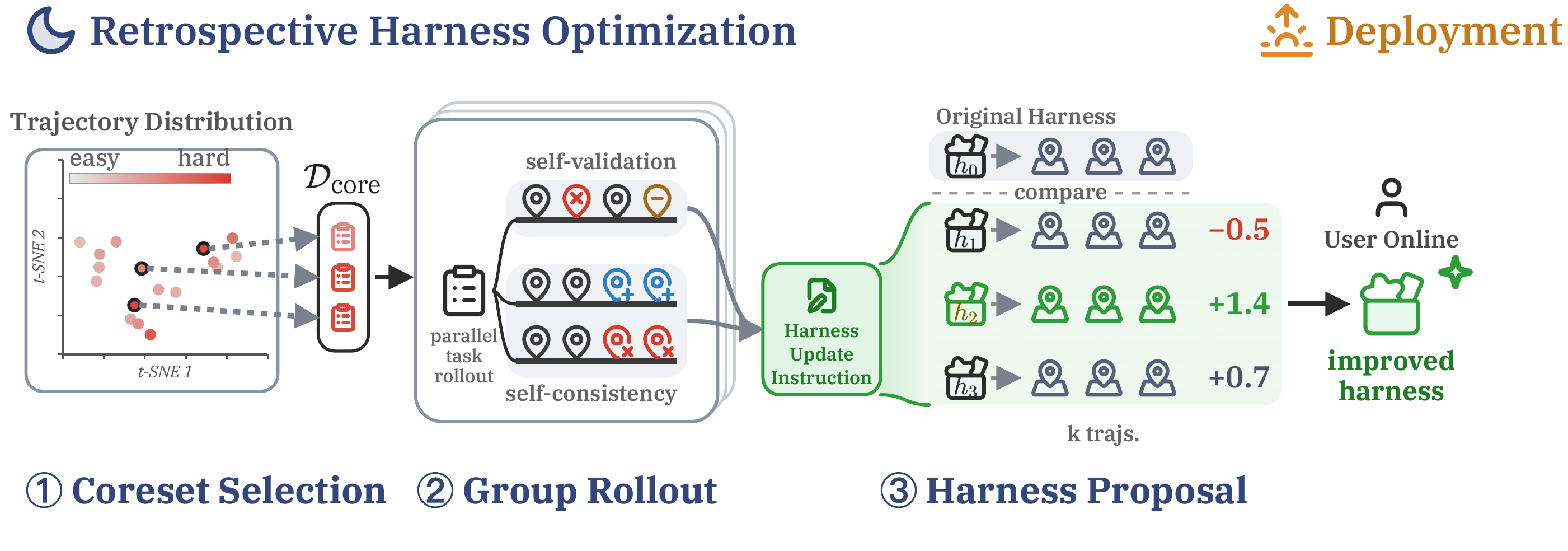
Pan et al. propose a self-supervised method for optimizing the agent harness with unlabeled trajectories. Named Retrospective Harness Optimization (RHO), the technique involves (1) selecting a diverse set of challenging tasks from history, (2) re-solving the tasks, and (3) analyzing re-solved rollouts to propose updates to the harness.
- Coreset Selection: The trajectories are ranked by language-model-derived difficulty while satisfying a diversity constraint. RHO then selects the tasks behind the hardest, most diverse trajectories.
- Group Rollout: Each selected task is run multiple times, and the rollouts are evaluated for self-validation and consistency, producing a per-task instruction.
- Proposal: RHO turns those per-task diagnoses into a few possible harness updates, tests them on the selected tasks, and keeps the update that its own pairwise judge prefers over the original harness.
The authors report that one RHO pass improves SWE-Bench Pro from 59% to 78%, with smaller but positive gains on Terminal-Bench 2 (71% to 76%) and GAIA-2 (29% to 37%).
Read more
SWE-Marathon: can agents do long-horizon software work?

SWE-Marathon is a new benchmark by Desai et al. that measures agents’ ability to perform long-horizon software work. Unlike small patch-style coding benchmarks, its tasks are closer to multi-hour project work: - Porting libraries from one language to another - Creating product clones - Implementing or training ML models to reach certain performance - Optimizing kernels
At pass@1, the authors report that the best configuration, Claude Opus 4.8 with Claude Code, solves only about 26% of tasks, showing that frontier agents still have a lot of room to improve on project-scale software work.
Read more
Personal Anecdote: write-time guardrails for ever-increasing USER.md

I use Hermes Agent to automate day-to-day tasks like finding papers, comparing computers, and editing music. Because Hermes can update its own user memory (USER.md), it slowly accumulated preferences that were useful somewhere but too specific to load everywhere: research interests, electronics I own, GitHub workflow rules, and so on. This meant that every extra line became context the agent carried into unrelated tasks.
My first attempted fix was to manually move entries in user memory to stop treating USER.md as a notebook. I moved domain-specific rules into narrower places: audio advice into an audio skill, GitHub workflow rules into GitHub skills, visual-style notes into project docs, and one-off ideas into the knowledgebase or GitHub issues. That cleanup was measurable: USER.md went from about 40 entries to 8 broad preferences.
But cleanup was only a partial solution. New entries still piled up, so recently I started testing memory-routing decisions against examples from past cleanups and moved the routing rule to the moment where the agent decides whether to save something. I could not gather quantitative results yet because the metric is noisy, but the current entries seem cleaner.
Subscribe to Agents in Practice
Get new issues of Agents in Practice — a newsletter summarizing exciting new research and applications in agentic AI — delivered to your inbox.